Feb 26, 2026
AI Ran Out of Internet Data. Protege Just Raised $30M to Unlock What Comes Next.
A fundraising interview with Bobby Samuels, Co-founder of Protege
Raise Report
Building the Data Infrastructure Layer for AI

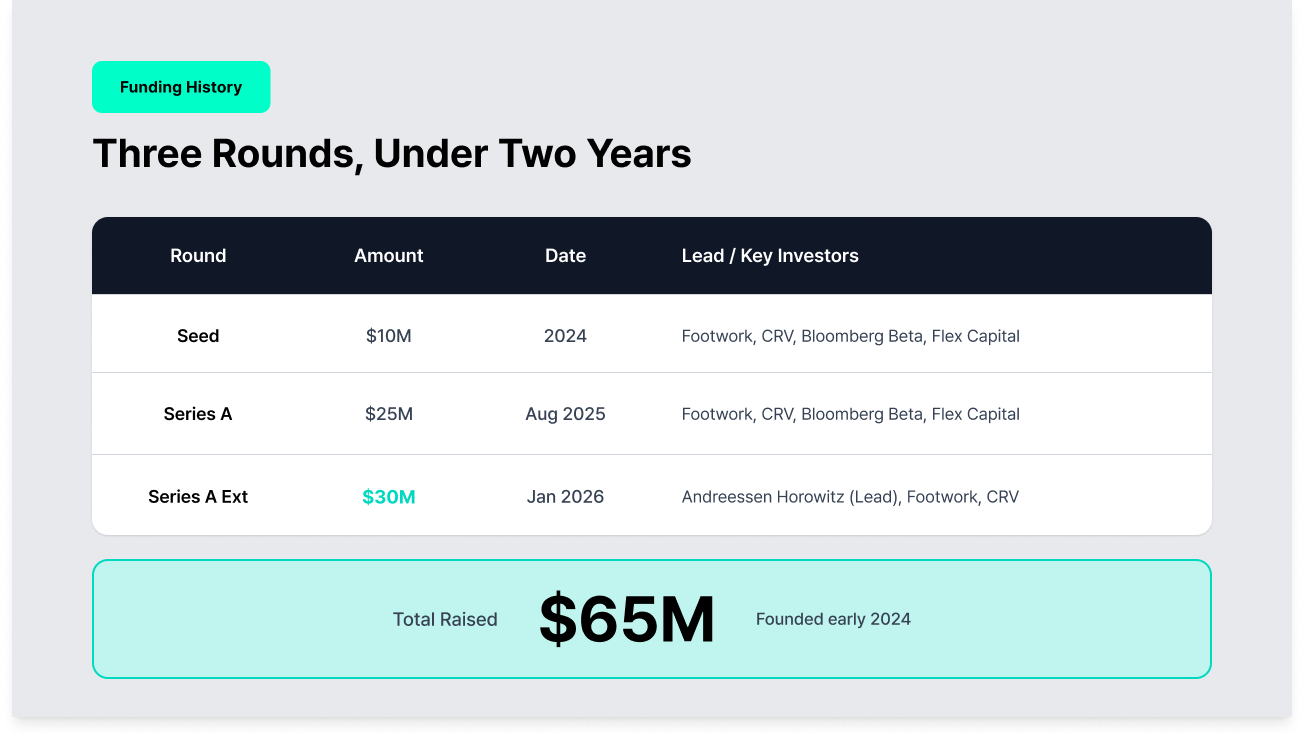
Protege has raised a $30 million Series A extension led by Andreessen Horowitz (a16z). Returning investors Footwork, CRV, Bloomberg Beta, Flex Capital, and Shaper Capital also participated, bringing total funding to $65 million. It is the company's third round in under two years since its founding in early 2024.
Protege is building the infrastructure that connects holders of valuable real-world data to the companies building frontier AI. Training the next generation of AI models requires far more than text scraped from the internet. It requires data generated from people living their normal lives: de-identified hospital records, sports footage, podcast recordings, surgical videos, and motion capture data.
But this data is scattered across thousands of institutions, bound by privacy regulations, and has never been packaged for AI use. Protege aggregates it, curates it, handles de-identification and licensing, and delivers it to AI companies in a ready-to-use format.
The new capital will fund expansion beyond Protege's current four domains (healthcare, video, audio, and motion capture) into more than ten new verticals, while deepening its data partner network and scaling the team.
Two Exits, One Thesis
Protege is not a first-time founder story. It is the product of two operators who already built and exited two of the largest data companies of the software era, then came back because they saw the biggest data opportunity of their careers sitting wide open.
Protege's co-founders Bobby Samuels and Travis May built and exited two of the largest data companies of the software era: LiveRamp (NYSE: RAMP, market cap approximately $1.8 billion) and Datavant ($7 billion merger). This is the third time they are working together, and their entire thesis for Protege comes from what they learned building data networks across both companies.

"One of the things that LiveRamp taught me was in the world of data networks, it is supply. You gotta figure out the supply and then you figure out demand. I'd say for us now, supply is probably our key constraint, not demand."Bobby SamuelsCEO of Protege
At Datavant, Bobby led the privacy business called Privacy Hub before the $7 billion merger. That experience gave him something less obvious than domain expertise: a gut-level framework for handling sensitive data that now runs through everything Protege does.

"One of the big values that we have is the loved ones test, which is if a loved one saw what we were doing, would they be proud of it?"
"Anytime we run into any sort of question, whether that's dealing with a partner or a data type, or a model builder or an investor, we always run it through that lens."
"We're dealing with really sensitive stuff and we owe it to everyone to work with the data accordingly."Bobby SamuelsCEO of Protege
The founding team includes Chief Scientific Officer Engie Zon, a professor Bobby met through Datavant, and CTO Richard Ho, who leads engineering. Bobby is blunt about the division of labor: "I'm not an engineer. I am not a data scientist. I can usually ask the right questions or something close to the right questions. But without Engie and Richard, we wouldn't have a business."
The founding moment was simple. Travis had seen demand for AI training data in healthcare. Bobby believed the opportunity extended far beyond a single vertical. Once that clicked, speed became everything.
Public data was running out, AI companies were desperate for new sources, and waiting even a few months meant losing the window. As Bobby recalls, when a couple of major 2025 deals materialized that would not have been possible had they started three months later, the urgency proved justified.
"When we were coming up with this idea, Travis said, look, I've seen this need for training data in healthcare. And then I was like, I think this is everywhere. And as soon as we got there, it was just like, let's go."Bobby SamuelsCEO of Protege
The Internet Is 0.0000002% of the World's Data
2024 was the year of scraping publicly available internet data. AI companies consumed massive volumes of text, images, and code from the open web to train their models.
Bobby sees a hard boundary on how far that can go. He draws a line between three categories:
"Synthetic data is data that is created by AI to train AI. Manufactured data is data that is created by humans, specifically for AI. Real-world data is data that is created by humans living their lives, and that is being used to train."Bobby SamuelsCEO of Protege

"Ultimately, you want data that is most representative of the human experience, and real-world data is that subset."
"Synthetic data is like reading a book, having the model then write a book, and trying to learn more from what you wrote. It just doesn't make sense."Bobby SamuelsCEO of Protege
The scale of what's still untapped puts this in perspective. A single Common Crawl release, a snapshot of the entire open web, contains hundreds of terabytes of uncompressed content. Meanwhile, total global data is set to surpass 175 zettabytes (175,000,000,000 terabytes). The entire internet accounts for a fraction of a percent of all data in existence.
Throughout 2024, the prevailing narrative in AI was that the industry was running out of data. Bobby watched that conversation unfold and thought it was fundamentally wrong.
"There was all this coverage of, 'we're out of data, we're out of data,' and we firmly believe that that's wrong. We're not out of data, we're out of public data."
"If you think about all the data that's generated, we're just data machines. Most of it is not captured. And so when you say we're out of data, it's like, no, we're not."
"We're out of publicly available scrapable data, but the vast majority of the world's data is still to be gleaned."Bobby SamuelsCEO of Protege
Why AI Companies Can't Source Real World Data Alone
AI companies know real-world data matters. So why can't they get it themselves? Because there are structural bottlenecks on both sides of the market.

On the AI company side, even the largest foundation model builders lack the internal resources and time to source, negotiate, transform, audit, and deliver data from thousands of partners, each with their own industry-specific nuances. Direct deals like the ones between Reddit and OpenAI or Google exist, but they are the exception, not the norm.
On the data holder side, the problem is the mirror image. Most organizations sitting on valuable data have no AI expertise, no sense of what their data is worth, and no intention of building an AI sales team. Bobby explains with a real example.
"For a model builder, we are a one-stop shop for their data. For a data holder, their business may be something totally different."
"We work with a Polish soccer league and AI data's not their business, but we can be an extension of their business to help drive this totally new line of revenue in a way that's a very small lift for them."Bobby SamuelsCEO of Protege
Bobby explains the practical difference Protege makes on the buyer side with another example.
"We've worked with partners where they had these huge complex acts around healthcare that would've taken them a year plus to figure this out on their own."
"And because we had built all the relationships, we understood how the data could be married together, we understood the privacy constraints, we understood how the delivery needed to happen."
"We were able to do all this in the course of weeks instead of years."Bobby SamuelsCEO of Protege

"I think the industry that Scale and others are participating in is really significant, but it's not our area."
"We're good at data and real world data and building those networks. We're not an annotation or labeling firm and we really stick to what we do."Bobby SamuelsCEO of Protege
$30 Million GMV and a Flywheel Taking Shape
In 2025, Protege recorded over $30 million in GMV, growing more than 20x year over year. The company now works with hundreds of data partners and dozens of customers across industries and around the globe, including the majority of the Magnificent Seven. An early concern was whether AI data deals would be one-time purchases. Instead, the majority of early customers signed multi-year deals or expansion contracts within six months.

The business has started to exhibit a flywheel dynamic. Foundation model companies that originally came to Protege for healthcare data now source audiovisual and other data types through the platform as well. More data attracts more buyers. More buyers attract more data providers.
"So much of our business is around trust from data partners and model builders that we're doing right by them. And it's something that we hold sacred."
"The trust is sacred. We've been able to establish that quickly, and now we need to just continue to build on that, because it's the core of the secret sauce."Bobby SamuelsCEO of Protege
The revenue model reinforces that trust. Rather than one-time data sales, Protege uses a royalty-based revenue share with its data partners. Partners earn payouts each time their data is used. Bobby says the structure was as much about speed as principle: "We chose the royalty model in part because it really aligns incentives: you make money when we make money. And it made it easier for folks to just move faster." Protege has already distributed tens of millions of dollars to its data partners.
Real World Data Will Power Every Layer of AI
Protege currently operates across four domains: healthcare, video, audio, and motion capture. Existing customers are already requesting data types outside those verticals. The plan for 2026 is to expand into more than ten new domain areas, deploying general managers to run each as an independent business unit and making strategic investments to quickly build a critical mass of data supply.
"I fundamentally believe that AI's impact on the world can be and hopefully is extremely positive. If we can play a role in accelerating the development of healthcare and its utilization of AI, that's huge."
"People live longer and have richer lives. And it's not just healthcare."
"If you're an 18-year-old kid, you don't have much resources, but you have a great idea for a story, 20 years ago you'd have to figure out how to cobble together the resources and you probably couldn't. Now the ability for folks to tell stories is so much more at people's fingertips."Bobby SamuelsCEO of Protege
The team's view is that real-world data will underpin every layer of the AI stack, from pre-training to post-training, fine-tuning, evaluation, RAG, and continuous learning, across every industry. What started as a validation of AI training and evaluation data in a few domains is expanding into something much larger.
Daisy Wolf, Partner at Andreessen Horowitz, framed the investment this way: "The next era of AI will be shaped by who can responsibly unlock access to the world's most valuable data."
Protege is targeting a nine-figure GMV in 2026 and $1 billion in GMV within three years. When asked how he will know the company has succeeded, Bobby resists the idea of a finish line.

"Protege will have succeeded if we can meaningfully accelerate the development of responsible AI."
"But ultimately, the work is never done. Microsoft started 50 years ago and they are still pushing hard. When you're building a company, you don't really think about the finish line."
"It's just how do you build something impactful and hopefully more and more impactful over time."Bobby SamuelsCEO of Protege
He pauses, then offers a simpler version.
"To build great AI, you need great data, and that's what we make possible."Bobby SamuelsCEO of Protege
Further Reading
About This Funding Round
Bobby Samuels on a16z's Raising Health Podcast
Understanding the AI Data Landscape
Explore more